Abstract
Generating portrait images by controlling the motions of existing faces is an important task of great consequence to social media industries. For easy use and intuitive control, semantically meaningful and fully disentangled parameters should be used as the modifications. However, many existing techniques do not provide such fine-grained controls or use indirect editing methods i.e. mimic motions of other individuals. In this paper, a Portrait Image Neural Renderer (PIRenderer) is proposed to control the face motions with the parameters of three-dimensional morphable face models (3DMMs). The proposed model can generate photo-realistic portrait images with accurate movements according to intuitive modifications. Experiments on both direct and indirect editing tasks demonstrate the superiority of this model. Meanwhile, we further extend this model to tackle the audio-driven facial reenactment task by extracting sequential motions from audio inputs. We show that our model can generate coherent videos with convincing movements from only a single reference image and a driving audio stream.
Network Architecture
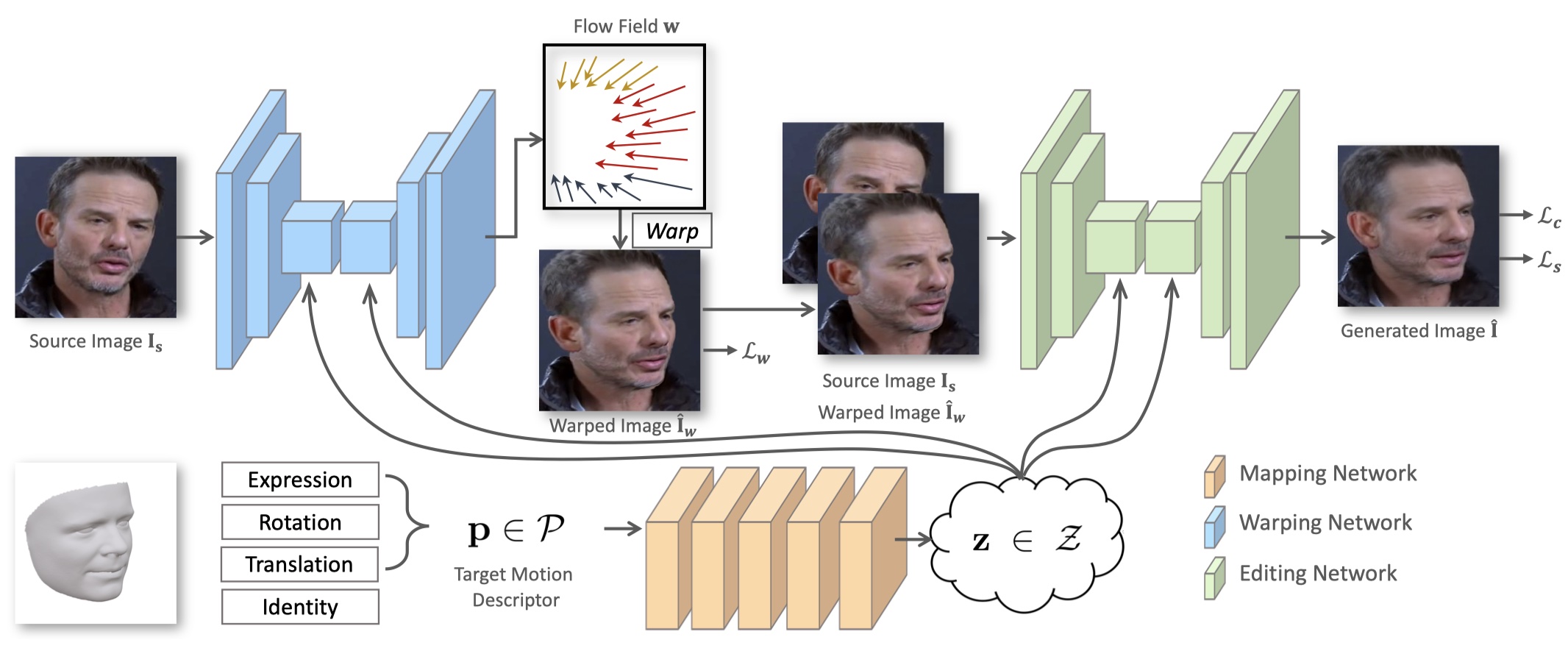
The proposed PIRenderer can synthesis portrait images by intuitively controlling the face motions with fully disentangled 3DMM parameters. The architecture of this network is shown below.
The Mapping Network
The mapping network is used to product latent vectors from the motion descriptors. The learned latent vectors are used to control the warping network and the editing network to synthesize images with accurate motions.
The Warping Network
The warping network is used to estimate the motions between source images and target images. It takes the source image and the latent vector as inputs and generates the flow field containing the coordinate offsets specifying which positions in the sources could be sampled to generate the targets.
The Editing Network
Although the warping network is efficient at spatially transforming the source images, it is limited by the inability to generate contents that do not exist in the sources. Meanwhile, artifacts introduced by the warping operation will lead to performance decline. Therefore, an editing network is designed to modify the warped coarse results and generate realistic target images.
Results
Intuitive Portrait Image Editing


Motion Imitation

Audio-Driven Facial Reenactment
